
前回の記事では、2026年末の日経平均株価およびS&P 500を予測するにあたり、どのような前提で、どの経済データを選定したのかについて整理しました。
株価予測というと、「どのAIモデルを使うか」や「精度は何%だったか」に注目が集まりがちですが、実務的な視点で見ると、AIモデル作成以前の工程が結果の大半を左右すると言っても過言ではありません。
特に、
- 時系列として扱ってはいけないデータが混ざっていないか
- 過去情報としてどこまで遡るべきか
- どの特徴量が本当に意味を持っていそうか
- データの形(分布)がAIにとって学習しやすい状態か
といった点は、派手さはないものの、ここを誤ると「当たっているように見えるAI」が簡単に出来上がってしまう領域です。
前回選定した各種経済データに対して、
- 未来情報の混入を防ぐためのチェック
- ラグ変数の有効性検証
- データ分布を踏まえた変換方法の検討
- 特徴量同士の関係性の可視化と選別
- AIモデルに入力するためのスケーリング
といった 「地味だが、最も重要なデータ分析・加工工程」を順に解説します。
この工程は、「AIモデルにデータを入れれば何でも予測できる」という幻想ではなく、人間が行うべき作業でもあります。
以降で登場するAIモデルの結果を正しく理解するためにも、「なぜこの形にデータを整えたのか」という思考プロセスに重点を置いて説明していきます。
※ 本記事は技術検証の共有を目的としたものであり、投資助言ではありません。予測結果は外れる可能性があります。
1. データリーケージのチェック
AIで時系列予測を行う際、最も警戒すべき問題が「データリーケージ(Data Leakage)」です。これは、「本来は未来でしか分からない情報が、学習データに紛れ込んでしまう現象」を指します。厄介なのは、「データリーケージが発生しても、モデルはエラーを出さず、むしろ精度が良く見える」という点です。
つまり、「一番気持ちよく動いているAI」が、実は一番信用できない可能性があります。
今回の2026年日経平均株価予測では、特に以下の3種類のデータリーケージに注意して健全性チェックを行いました。
(1)時間軸由来のリーケージ(未来情報の混入)
株価予測における最も典型的なリークが、予測時点ではまだ存在しない情報を参照してしまうケースです。
今回の前提では、「2025年12月時点で入手可能な情報のみを用いて、2026年末を予測する」というルールを設定しています。
そのため、以下のチェックを全変数に対して確認しました。
- 経済指標の公表日とデータの日付が一致しているか
- CPI、失業率、鉱工業生産指数など、公表ラグを持つ指標が「発表前の月」に割り当てられていないか
- 月末終値予測に対して、月途中でしか分からない情報を使っていないか
特にマクロ経済データは、「値は月次だが、分かるのは翌月以降」というケースが多く、ここを雑に扱うと簡単に未来情報が混入します。
【参考】
| 指標名 | 公表時期(目安) | 具体例(2025/12のデータが判明するタイミング) |
|---|---|---|
| 消費者物価指数(CPI) | 翌月中旬 | 2025年12月分CPI → 2026年1月中旬に公表 |
| 失業率 | 翌月初旬~中旬 | 2025年12月分失業率 → 2026年1月上旬に公表 |
| 鉱工業生産指数(IP) | 翌月末~翌々月初(速報) ~翌々月中旬以降(確報) |
2025年12月分のIP → 2026年1月末速報 → 2026年2月中旬以降確報 |
| マネーストック(M2) | 翌月中旬~下旬 | 2025年12月分M2 → 2026年1月中旬~下旬に公表 |
| 為替レート(USD/JPY) | 市場取引と同時 | 2025年12月31日のUSD/JPY → 同日中に確定 |
| 原油価格(WTI) | 市場取引と同時 | 2025年12月31日のWTI終値 → 同日中に確定 |
| VIX指数(恐怖指数) | 市場取引と同時 | 2025年12月31日のVIX終値 → 同日中に確定 |
| TOPIX / 日経平均 | 市場引け後に即時確定 | 2025年12月31日の日経平均終値 → 市場引け後に確定 |
| NYダウ / S&P 500 | 市場引け後に即時確定 | 2025年12月31日のS&P 500終値 → 市場引け後に確定 |
| 国債利回り(2年・10年) | 市場取引と同時 | 2025年12月31日の米国国債利回り → 同日中に確定 |
一例として、未来情報の混入のチェックは、モデルの更新時点を基準として、「その時点で取得可能な学習データがどこまでか」を逆算する形で行います(図1参照)。
欠損値補完などの特別な処理を行わない場合、判断手順は以下の通りです。
①モデル更新時点(基準日)を決定します。
② 基準日において使用可能な説明変数のうち、最も公表が遅い変数に合わせて学習データの使用上限月を決定します。
③ 予測対象が翌年12月であるため、10月までの学習データを用いて、翌年12月までの月末株価を予測します。
このように、「使えそうだから使う」ではなく、「その時点で本当に存在していたか」を基準に判断することが、時系列予測におけるデータ健全性の最低条件となります。
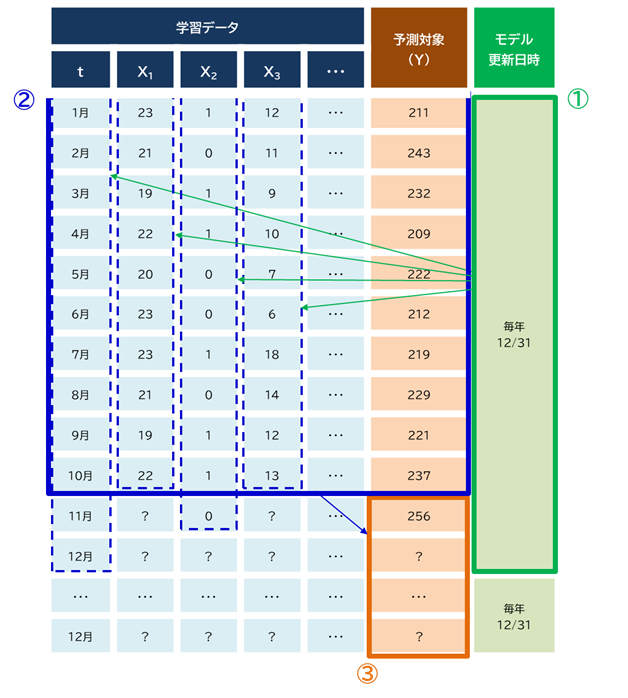 図1:時間軸のリーケージに関する判断
図1:時間軸のリーケージに関する判断
(2)前処理由来のリーケージ(学習・テストをまたぐ情報利用)
もう一つ見落とされやすいのが、前処理の段階で全期間の情報を使ってしまうリーケージです。
例えば、
- 全期間データで平均・分散を計算して標準化
- 全期間データで欠損補完や外れ値処理を実施
- 全期間データでの主成分分析(PCA)による変数削除
といった処理は、一見無害に見えますが、テスト期間(=未来)の統計量を学習時に使っているため、明確なデータリーケージになります。
本検証では、
- スケーリング
- 欠損補完
- 特徴量変換
のすべてについて、学習期間のみでパラメータを算出し、テスト期間には適用のみを行うという手順を厳守しました。
この手順を踏まない限り、「本番では再現不可能な精度」が簡単に出てしまいます。
(3)目的変数由来のリーケージ(結果を説明する変数の混入)
株価予測では、株価そのものから派生した変数が、意図せず説明変数側に混入するケースにも注意が必要です。
例えば、
- 予測対象期間を含む移動平均
- 年間変化率を計算する際に、年末価格を含めてしまう
- 主成分分析(PCA)による変数削除時に予測対象のデータも含めてしまう
これらは、形式上「別の特徴量」でも、実質的には答えを横から覗いている状態になります。
今回の検証では、
- Lagを限定的に使用
- 計算に未来の株価が含まれる特徴量はすべて除外
- 目的変数と同一期の値を使う変換は禁止
といったルールを設け、説明変数と目的変数が一方向になるよう設計しました。
なぜ、ここまで厳密にやるのか・・・と疑問に思う方もいるかと思います。
データリーケージは、「本番では使えないAIを、最高の精度に見せる魔法」のようなものです。
特に今回のような
- 年単位の長期予測
- データを大量に扱うケース
では、データリーケージに気付かないまま議論を進めるリスクが極めて高いです。
だからこそ、私はモデル構築より先に「このデータは本当に使っていいのか?」を疑い続ける工程を最初の重要ステップとして位置付けています。
2. ラグ変数の有効性検証
時系列予測で大事なのは、
「今の値は、過去の何日前(何期前)まで影響を受けているの?」
を把握することです。
そこで、ラグ変数(過去の値)をどこまで入れるべきかを、統計的に見積もるためにACF(自己相関)とPACF(偏自己相関)を使います。
ACF(自己相関):
- 「今」と「過去」の相関をそのまま見る
→「過去がどれくらい先まで影響するか」を確認する道具
例:「3日前の値と今日の値って、どれくらい似てる?」
PACF(偏自己相関):
- 「他のラグの影響を取り除いて」相関を見る
→「直接効いてるラグがどこまでか」を確認する道具
例:「3日前が効いてるように見えるけど、それって実は1日前や2日前由来じゃない?」
ACFやPACFを使用する目的は、ラグは増やせば増やすほど情報は増えますが、
- ノイズが増える
- 過学習しやすくなる
- AIモデルの学習が不安定になる
ので、闇雲に増やさず「効きそうなラグだけ」絞り込みたいわけです。
ACFとPACFをチェックする時のポイントとしては、以下の通りです。
1) 定常性の確認:
ACFがいつまでも下がらない場合、データにトレンドが含まれている(非定常)可能性があるため、差分をとってからプロットを再確認します。
2) 信頼区間(青い網掛け):
グラフ上で、青い網掛け(通常95%信頼区間)を超えている棒が「有意な相関」を持つラグです。すなわち、「どのラグ(過去の時点)でグラフの棒が信頼区間(青い領域)を超えるか」を確認します。
3) ラグ0(最初の棒):
通常1(100%の相関)になるため無視します。
また、AR(自己回帰モデル)が強いときは、過去の値が「連鎖」して効きます。
ARはざっくり、「今日の値 = 昨日の値 × 係数 + ノイズ」という世界です。
なので、一昨日の値は、直接というより、「一昨日の値 → 昨日の値 → 今日の値」みたいに鎖みたいに間接影響します。
- ACFは「直接も間接も全部込みの相関」を見るので、間接効果が残って、じわじわ減ります(尾を引く)。
- PACFは「途中(昨日)の影響を消して、純粋に“一昨日→今日”だけ」を見るので、AR(1)なら「昨日を押さえたら一昨日はもう追加情報ゼロ」になって、早い段階で0になります。
一方で、MA(移動平均モデル)は、「今日の値 = 平均値 + 昨日起きた突然のショック×係数 + …+(q期前まで)」という世界なので、「値そのもの」ではなくて「誤差(ショック)」の残り香で動いているイメージです。
したがって、
- ACFは「共通の誤差を共有しているか」で相関が出ますので、MA(q)はq期前までしか誤差を共有しないので、理屈としてラグqを超えると相関が出なくなり、スパッと切れます。
- PACFは「間の影響を取り除くような調整をした後の残りの変数関係」なので、調整のせいで遠いラグにも小さい依存が残りやすく、結果として尾を引く形になりやすいです。
となります。
今回は、図2の通り、直近のデータ、半年前付近のデータ、1年前付近のデータが移動平均的な形でなく自己回帰的に効いてくると思われるので、直近・半年前・1年前の辺りのラグ変数を用いることにしました。
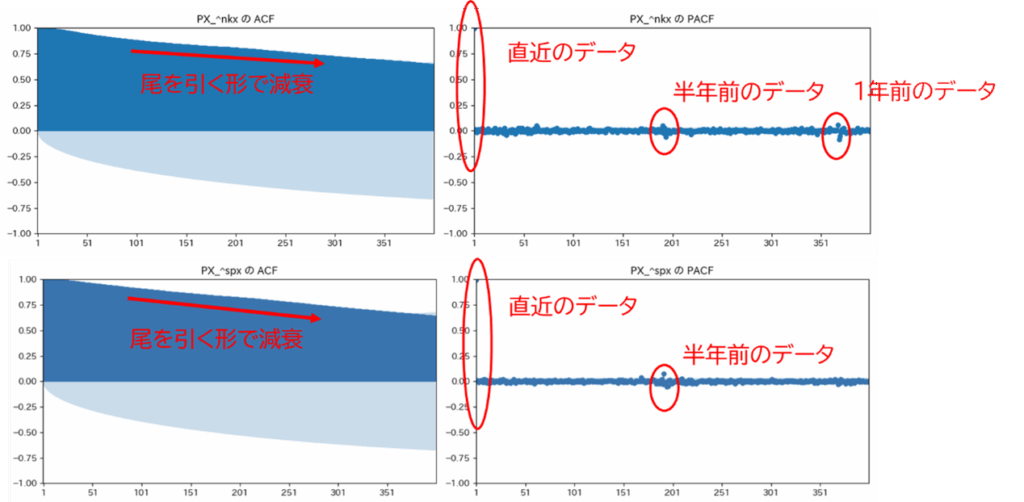 図2:日経平均株価、S&P 500のACFとPACF
図2:日経平均株価、S&P 500のACFとPACF
3. 次回予告
本記事では、AIモデルを構築する前段階として、
- データリーケージを防ぐためのチェック
- 時系列として扱う際のラグ変数の考え方
といった、「AIに渡す前のデータ設計」について解説しました。
これらはいずれも、モデルの種類に関係なく必ず必要となる工程であり、ここを誤ると、どれだけ高度で複雑なAIを使っても、再現性のない(精度の低い)予測結果になってしまいます。
次回は、ここで整えたデータを前提として、
- データ分布を踏まえた変数変換方法
- 似た情報を持つ変数をどのように整理したのか
- AIモデルに入力するためのスケーリングをどう判断したのか
といった、特徴量の効果検証や前処理設計などを中心に詳しく説明する予定です。したがって、「どの部分のデータを使うか」だけでなく、「データをどのような形で(どのように変換して)使うか」という部分も含めて解説していきます。


